Abstract
Taking inspiration from recent developments in visual generative tasks using diffusion models, we propose a method for end-to-end speech-driven video editing using a denoising diffusion model. Given a video of a talking person, and a separate auditory speech recording, the lip and jaw motions are re-synchronized without relying on intermediate structural representations such as facial landmarks or a 3D face model. We show this is possible by conditioning a denoising diffusion model on audio mel spectral features to generate synchronised facial motion. Proof of concept results are demonstrated on both single-speaker and multi-speaker video editing, providing a baseline model on the CREMA-D audiovisual data set. To the best of our knowledge, this is the first work to demonstrate and validate the feasibility of applying end-to-end denoising diffusion models to the task of audio-driven video editing.
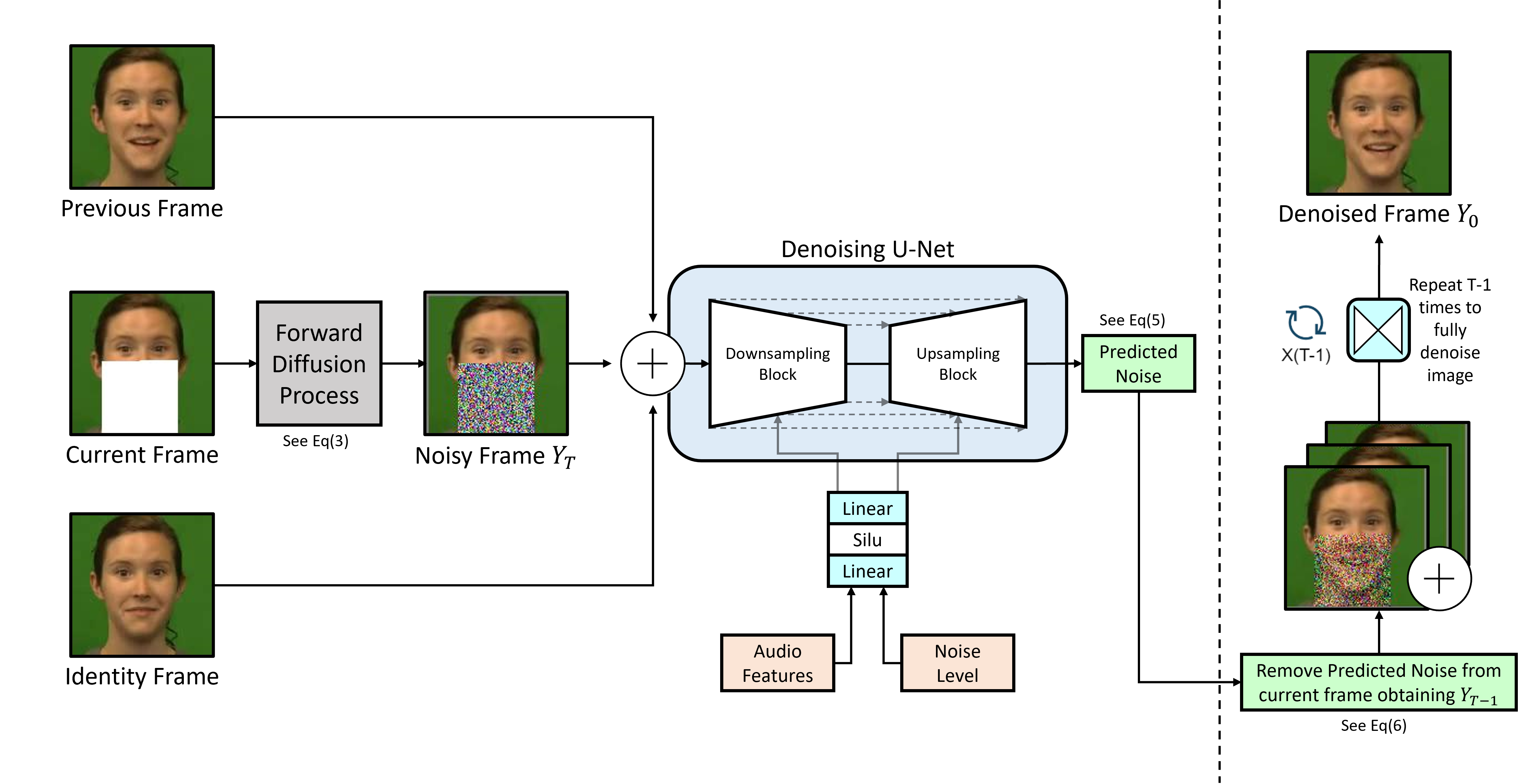
High-Level Overview of Network Architecture including the forward and backward diffusion processes.
Videos Generated By Our Multi-Speaker Model with Unseen Identities
Note, that while these results look really nice, the models still suffer from a lack of prolonged training time due to limitations in our available hardware. We recommend users with access to beefier GPUs to continue training from our pretrained checkpoints! More details regarding the training set up available in the paper :) Don't forget to click the arrow icon to cycle through the videos!
"I wonder what this is about"
"Its eleven o clock"
"That is exactly what happened"
"The surface is slick"
"That is exactly what happened"
"I think Ive seen this before"
Paper PDF
BibTeX
@misc{https://doi.org/10.48550/arxiv.2301.04474,
doi = {10.48550/ARXIV.2301.04474},
url = {https://arxiv.org/abs/2301.04474},
author = {Bigioi, Dan and Basak, Shubhajit and Stypułkowski, Michał and Zieba, Maciej and Jordan, Hugh and McDonnell, Rachel and Corcoran, Peter},
title = {Speech Driven Video Editing via an Audio-Conditioned Diffusion Model},
publisher = {arXiv},
year = {2023},
copyright = {Creative Commons Attribution 4.0 International}
}